The semiconductor industry is undergoing its biggest shift in decades. AI is reshaping computing, creating demand for specialized hardware while displacing legacy components. This shift is most visible on three fronts: the transition from general purpose processors to AI-optimized chips, the use of high-bandwidth memory to handle AI’s data intensity, and the rise of ultra-fast interconnect solutions that bind AI servers together. Together, these shifts mark a structural reset likely to define the semiconductor sector for decades.
But the transformation doesn’t end there. The rise of AI supercomputing hubs, which are densely packed data centers optimized for high-speed networking and advanced cooling, has opened new markets for specialized server systems designers and infrastructure providers. At the same time, quantum computing is emerging as a breakthrough technology that could be critical in tackling some of society’s most complex problems across data simulation, drug discovery, national security, supply chains, and more.
In short, a generational computing transformation is in motion with profound implications for investors. Global semiconductor revenues could surpass $1 trillion by 2030, with AI chips driving a disproportionate share of that growth.1
To help capture this opportunity, we are introducing the Global X AI Semiconductor & Quantum ETF. The fund seeks to capture pure-play companies advancing AI semiconductors, compute systems, data center infrastructure, and quantum technology, aiming to provide differentiated exposure to the future of computing.
Key Takeaways
- The semiconductor industry is facing a structural transformation, as AI reshapes computing needs. AI is poised to drive most of the industry’s growth over the next two decades.
- Beyond AI chips, memory, and networking providers, specialized developers of AI supercomputing clusters are critical to building the infrastructure of the future.
- The Global X AI Semiconductor & Quantum ETF provides exposure to companies across the emerging AI semiconductor and quantum value chain, which is likely to define the next generation of global computing needs.
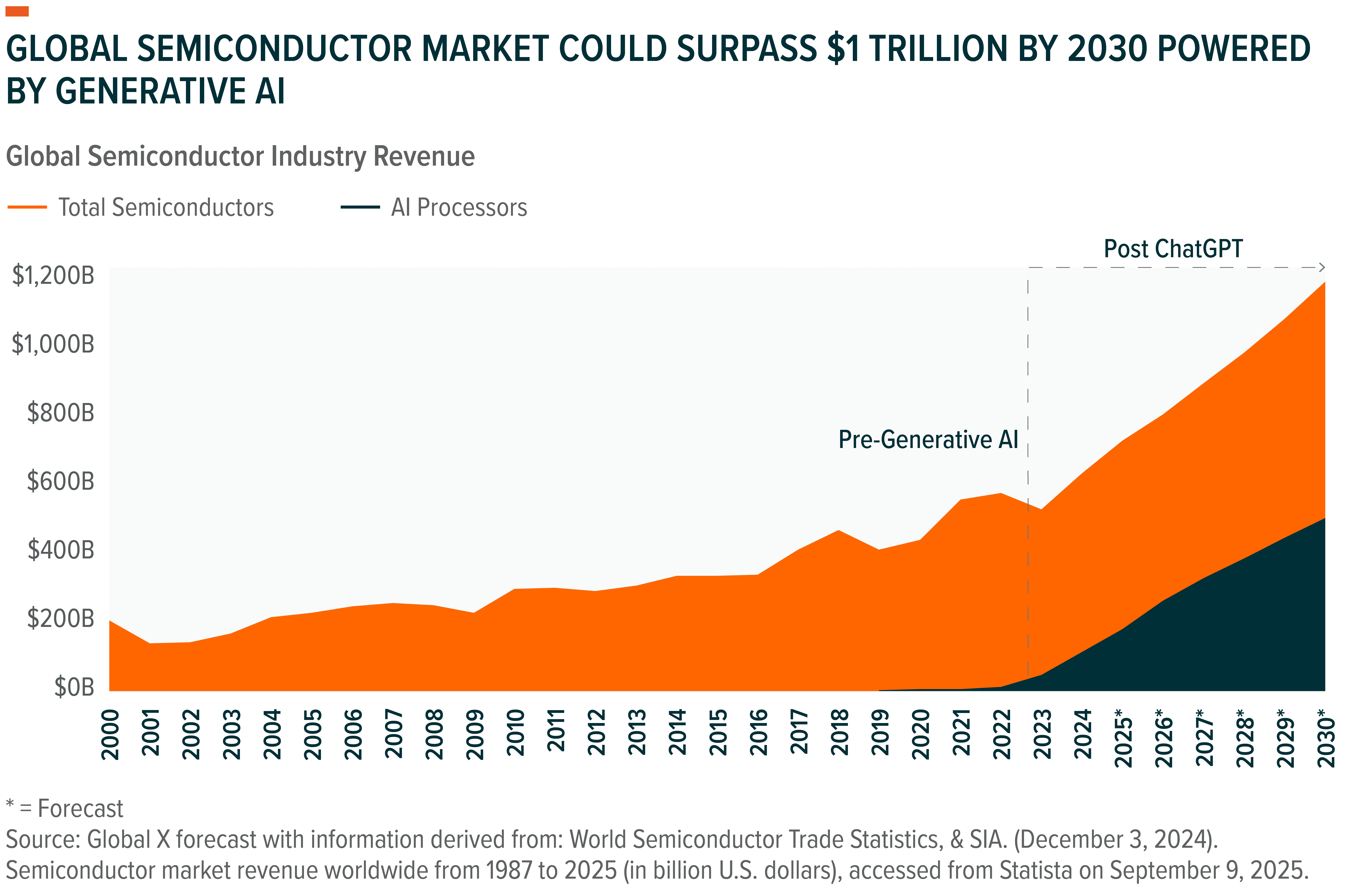
AI Is Reshaping the Semiconductor Industry
Semiconductors are the invisible backbone of the digital economy. Every app we open, every image we share, every file we store eventually passes through an ecosystem of chips, memory, storage, and networking hardware. Over the past three decades, this industry has scaled into a $627 billion market as of 2024, powering the rise of the global digital economy.2
For decades, computing was synonymous with the CPU. As transistor sizes shrank and performance roughly doubled every two years – a trend observed and popularized as Moore’s Law – CPUs became more powerful and efficient.3 That model worked well when computing was primarily about commonly-performed sequential tasks, such as running everyday software, crunching spreadsheets, or storing databases.
But the explosion of data, and the rise of data-intensive computing like machine learning or generative AI broke this paradigm. AI’s needs go beyond logic, demanding parallel processing to manage billions of data points and trillions of computations – a workload CPUs alone can’t efficiently handle. For example, GPT-3 was trained for roughly 34 days on 43 terabytes of data, which included a corpus of millions of books and Wikipedia articles.4
This emerging demand gave rise to the field of accelerated computing, which pairs CPUs with specialized processors for data-heavy workloads. The GPU, originally built for graphics, proved an ideal accelerator. In 2012, researchers trained the breakthrough AlexNet deep learning model on GPUs, and the results were a turning point: faster training and better performance.5 This advanced a new era in computing, and since then, GPUs and other accelerators have become the backbone of AI infrastructure.
As applications expand, so does the market for AI semiconductors and infrastructure. Big Tech platforms are in the middle of a massive infrastructure buildout, racing to construct state-of-the-art AI data centers. Nearly $6.7 trillion is likely to be spent on infrastructure by 2030 to keep up with current demand for AI computing, with nearly $3.1 trillion expected to be spent on AI chips and semiconductor.6
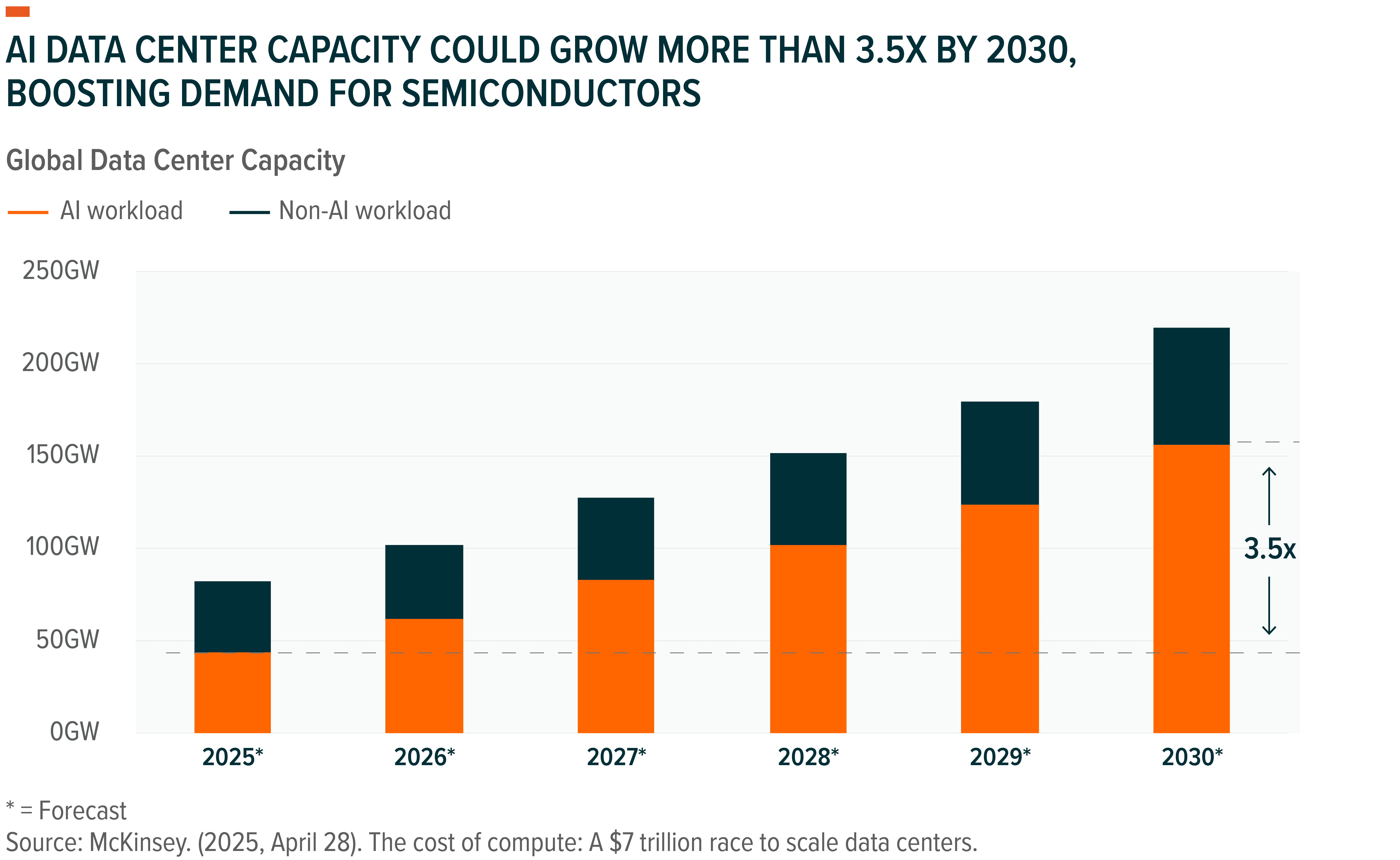
GPUs at the Core of AI: Poised to Capture Majority of Chip Sales
Over the past fifteen years, GPUs have steadily emerged as the preferred AI chip. Early adoption was driven by machine learning algorithms powering recommendation engines in e-commerce and streaming; news feed curation on social media; and predictive models in fields like finance and cybersecurity. The real inflection point came with the rise of large language models (LLMs) like ChatGPT, which redefined the scale of computational demands and pushed AI infrastructure into a new era.
Training and deploying LLMs requires infrastructure at unprecedented scale, forcing model developers and hyperscalers to acquire GPUs in record volumes. No company has benefitted from this chip boom more than Nvidia. With roughly 95% share in AI GPUs, its data center business made $146 billion over the past year – nearly 20 times its 2020 levels.7
And the cycle remains in full swing. Sustained Big Tech spending is generating strong demand for processors, while Nvidia’s Blackwell architecture promises substantial performance gains over prior generations.
In all, AI processors could attract over $500 billion in spending by 2030.8 In our view, Nvidia is positioned to retain its leadership in AI processing. At the same time, a growing group of next-generation chip providers – particularly those emphasizing inference workloads and efficiency – may also benefit.
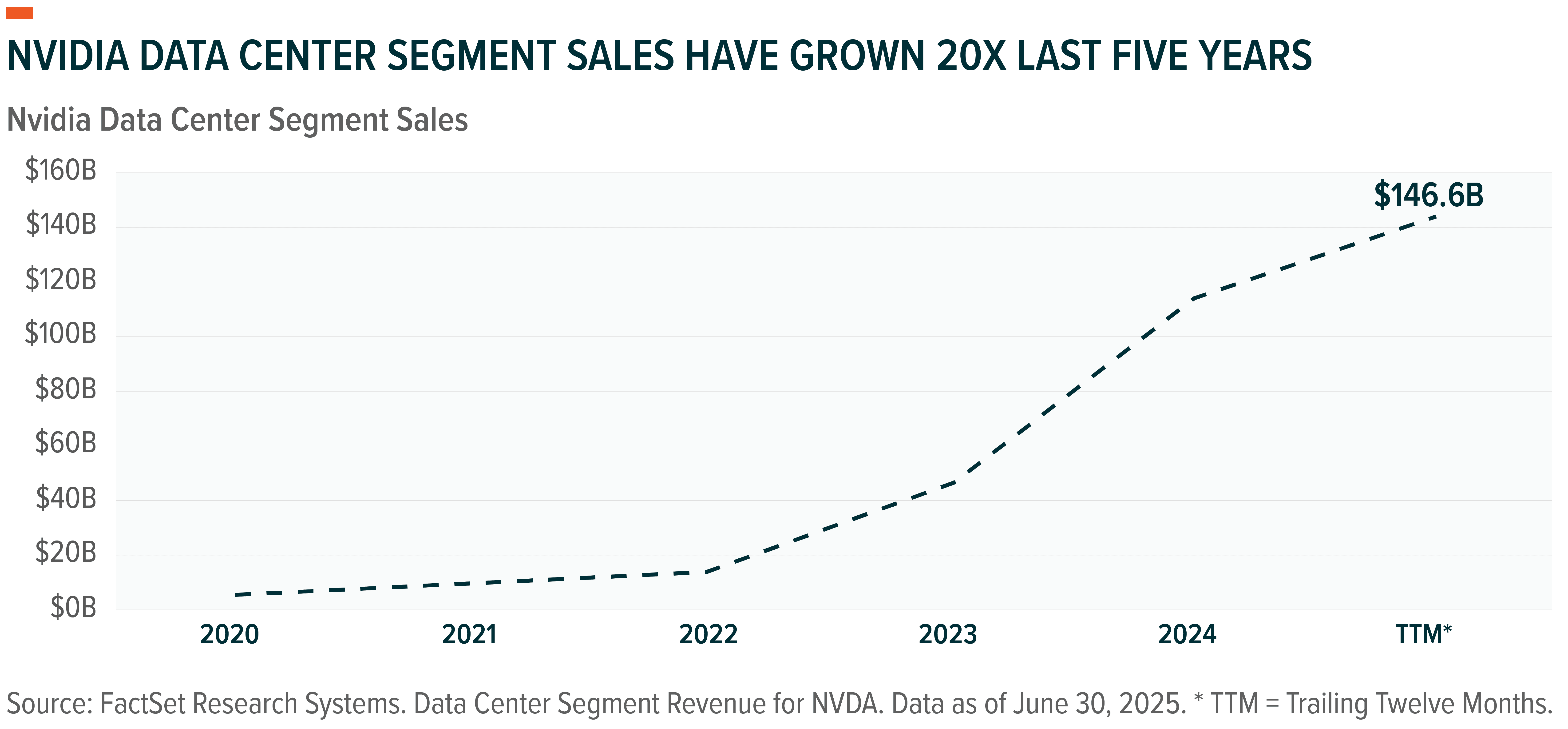
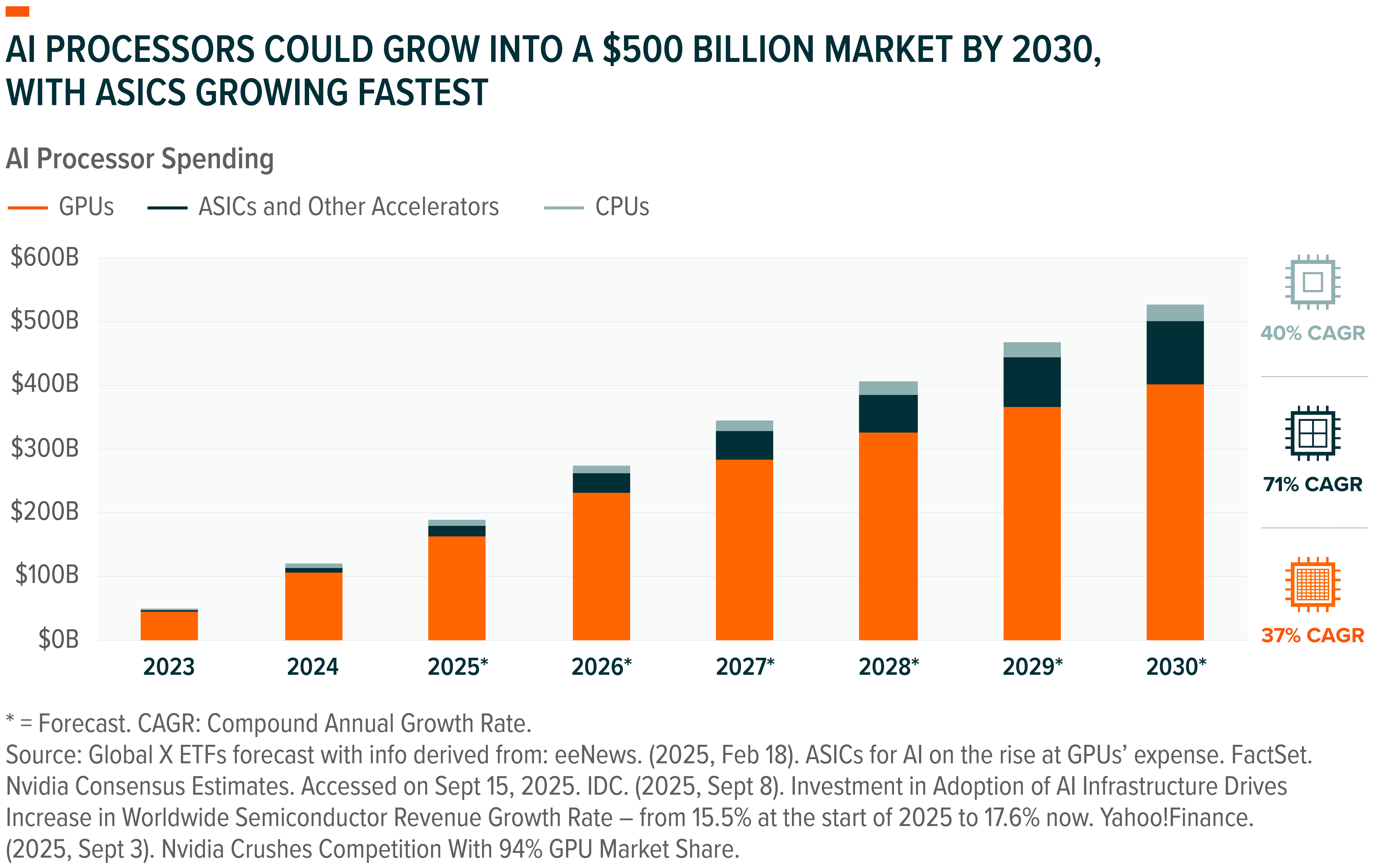
Beyond GPUs: ASICs Could Emerge as the Engines of Efficient AI Computing
GPUs remain the AI processor of choice where raw performance is critical. But once models are trained, the challenge shifts from performance to efficiency. This stage, also known as inference, is increasingly powered by alternative chip types such as application-specific integrated circuits (ASICs).
ASICs are designed for narrow and well-defined use cases, with the underlying silicon custom-built to offer higher performance and lower power consumption on those targeted tasks. Google’s Tensor Processing Unit (TPU), for example, accelerates workloads in Search and YouTube, while Tesla’s Dojo is optimized for processing the vast driving video captured by autonomous vehicles. Other hyperscalers – including Microsoft, Meta, and Amazon – are also investing billions into custom ASICs, programs that only make economic sense at the scale required to support their massive internal AI workloads.
Broadcom is emerging as one of the top players in AI ASIC development business, producing custom accelerators for buyers like Google. Its AI semiconductor business grew 63% year-over-year in its most recent quarter, bringing in $5.2 billion in sales. In fiscal year 2024, Broadcom made $12.2 billion in its AI chips and ASICs business, a major contributor to its $30.1 billion semiconductor segment.9
By 2030, ASICs and other specialized processors could generate nearly $100 billion in annual revenue, as the AI compute stack evolves and workloads increasingly demand solutions optimized for cost, scale, and specialization.10
Memory and Networking: The Critical AI Computing Stack Beyond Processors
Processors alone do not define AI performance. To function effectively at scale, AI clusters require equally advanced memory and networking systems to keep GPUs and other processors fully utilized. Without these, even the most powerful chips sit idle.
High-Bandwidth Memory: Powering Faster, Smarter AI
Data is the fuel for AI, and high-bandwidth memory (HBM) determines how quickly models can process that data. Positioned directly alongside processors, HBM moves information far faster than traditional memory, enabling AI chips to keep their compute cores fully utilized and deliver responses in quick turnaround times.11
HBM’s importance is most evident when users interact with AI models. As models scale and manage larger contexts – whether longer prompts or sequential, agentic tasks – they demand ever-greater memory bandwidth to keep pace. HBM enables this by supplying processors with the data management and throughput needed to complete tasks efficiently
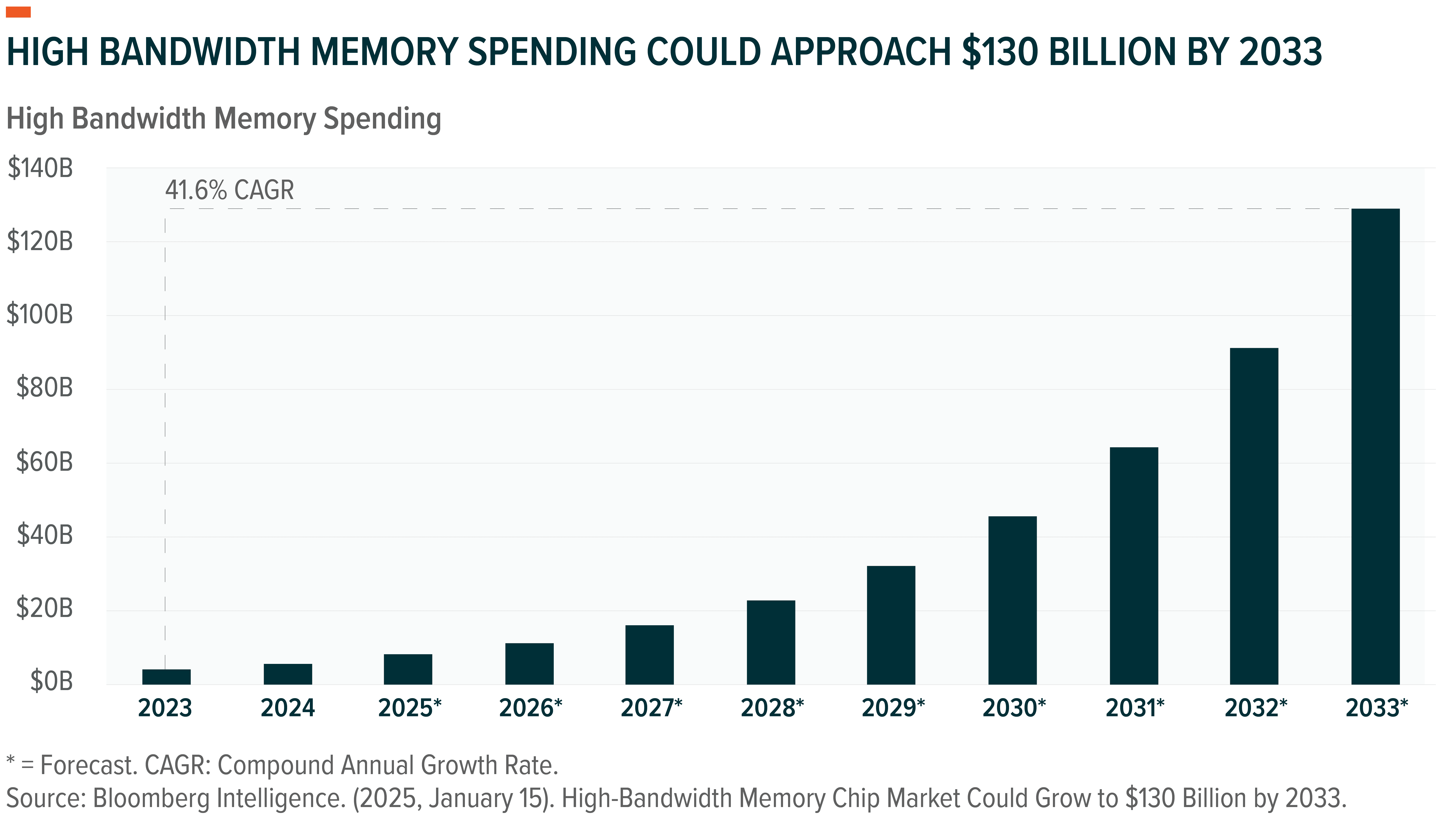
Demand for HBM is surging. The global high-bandwidth memory market is expected to grow from $4 billion in 2023 to over $130 billion by 2030, growing at a compound annual growth rate of 41.6%.12 SK Hynix remains the leading supplier of HBM solutions, with companies like Samsung and Micron quickly catching up on the technology.13
AI Networking: Maximizing Bandwidth and Minimizing Latency
AI processing also requires a wide array of high-speed networking solutions – whether to connect small processors within a single GPU, connect GPUs to each other, or interconnect large clusters of processors into supercomputer-scale networks. These systems are designed to minimize latency and maximize bandwidth across racks and data centers. As investments into new AI data centers scale, spending on such networking solutions has been growing in lockstep.
Data center-focused networking solutions are projected to grow from $20 billion in 2025 to $75 billion by 2030, representing a 30.2% annualized growth rate over that period.14 Key players across the AI networking value chain include Nvidia, Broadcom, Marvell, Cisco, and Arista Networks.
Foundries: Specialized Factories Fabricating AI Chips
Similarly, on the other end of the equation, designing and supplying chips at scale is also fueling demand for advanced foundries, led by Taiwan Semiconductor Manufacturing Company (TSMC). TSMC expects its AI accelerator revenues to double again in 2025 after a strong 2024 and are projected to grow at over 40% compound annual growth rate for the next five years.15 New chip fabrication facilities are set to attract nearly $1.5 trillion in total spending between 2024 and 2030.16
Compute Systems Enablers: Turning Standalone Servers into AI Supercomputers
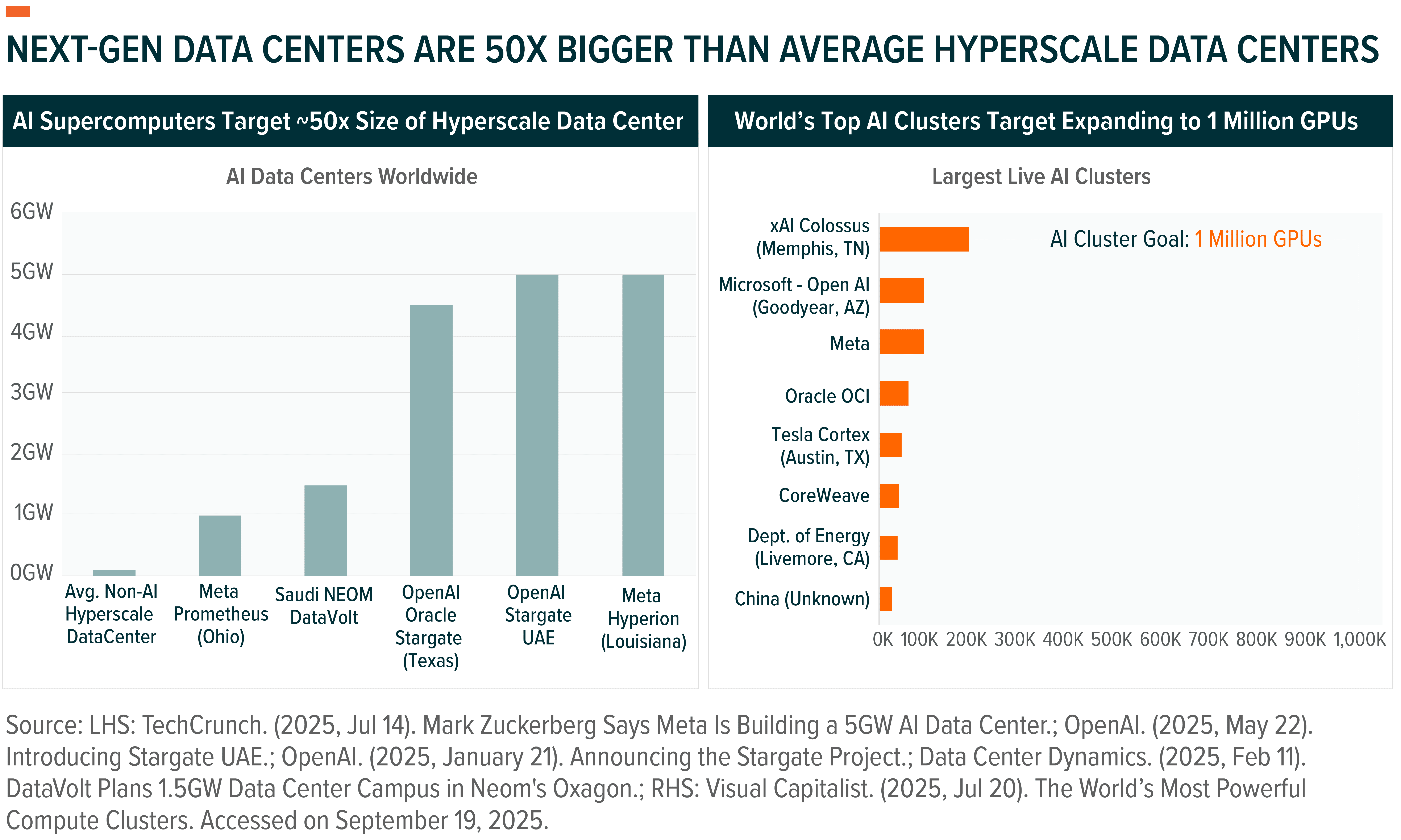
As AI demand grows, a new challenge is coming into focus: assembling chips into functional AI clusters at scale. Modern AI data centers can be thought of as a “supercomputer” for AI, with densely packed racks of GPUs, linked through ultra-high-speed networking systems to function as a single compute fabric. These clusters enable parallel processing across thousands – and soon across millions – of GPUs by ensuring low-latency, high-bandwidth communication between the processing nodes. In effect, the development and scale of these hubs is extremely critical to the industry’s ability to train larger models.
The industry is still in the early stages of scaling such systems. The largest known cluster to date, built by Elon Musk’s xAI, leverages more than 200,000 Nvidia H100 GPUs, setting the current benchmark of scale. Leaders such as CoreWeave are racing fast to add scale. Hyperscalers such as Meta Platforms, Oracle, or even OpenAI, are now planning multi-gigawatt facilities capable of hosting millions of AI servers, pointing to an order-of-magnitude leap in scale.17
A key role played in making these facilities possible is by server systems assemblers like Super Micro, HPE, and Dell, who combine infrastructure expertise with assembly of racks, to tackle what is likely emerging as the defining industrial challenge of this decade.
Data Center Equipment: Powering and Cooling AI Supercomputers
Power efficiency and management are also becoming key constraints for AI supercomputer performance. Modern hyperscale AI data centers can consume about 100 megawatts per site, enough to power 80,000 U.S. homes, with cooling alone accounting for 30–40% of operating costs.18 In such dynamics, traditional air-based cooling systems are reaching their physical limits. Liquid cooling can reduce energy used for cooling by up to 90%, while enabling higher-density GPU racks that can draw nearly ten times more power.19
This evolving dynamic makes the co-design of chips, racks, power distribution, and thermal systems critical. Bottlenecks in any one layer can constrain the performance of the entire cluster. Next-gen Nvidia Blackwell servers are shipping with direct-to-chip liquid cooling systems, reflecting the broader industry trend.20 The industry’s growth and expansion rely closely on this enabling ecosystem.
Quantum Computing: The Next Frontier Complementing AI
Quantum computers use qubits instead of traditional bits. While a bit can only be a 0 or a 1, a qubit can represent 0, 1, or both, at the same time. This unique property lets quantum computers handle certain problems that grow too large and complex for classical computers to manage.
The implications of this capability are profound. Problems that are mathematically intensive – such as optimization, molecular simulation, or cryptography – remain out of reach for even the largest AI clusters today but could become solvable with quantum computing. This could enable breakthroughs in drug discovery, climate modeling, advanced materials design, complex supply chain simulations, defense, corporate security, and more.
Crucially, quantum will not displace AI. Instead, it will complement and amplify it. AI models and agents are likely to remain in control, only to utilize quantum computers for complex simulation tasks.
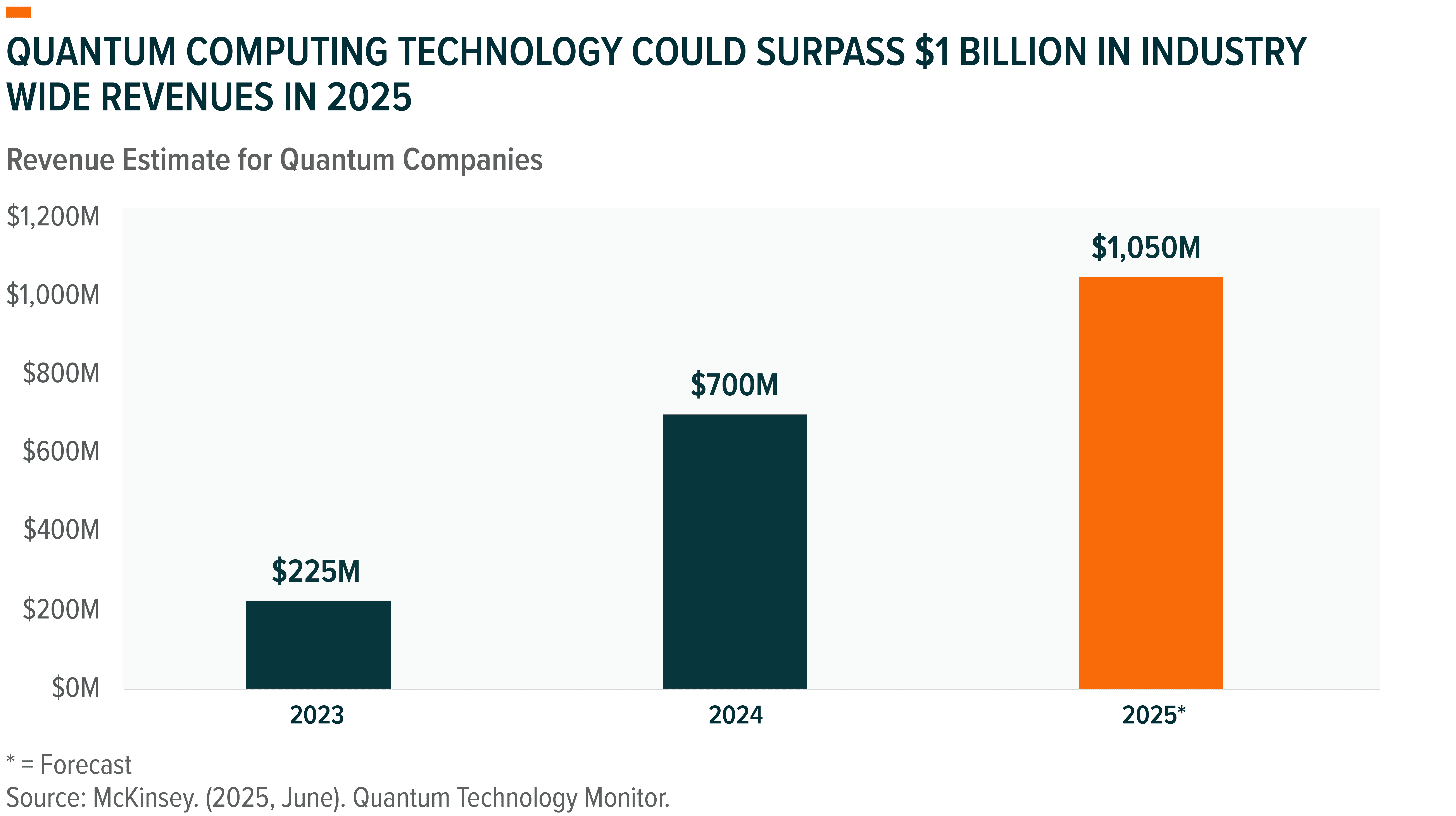
Notably, Quantum technology is still nascent, with the industry earning less than $1 billion in revenues in 2024.21 But momentum is building, and the opportunity is expected to scale to $10 billion in revenues by 2030.22 Big Tech giants and startups alike are racing to achieve quantum advantage, while governments are investing billions in national quantum initiatives.
CHPX: Targeting Full Stack AI Semiconductor and Quantum Opportunity
The Global X AI Semiconductor & Quantum ETF (CHPX) is an index based passive ETF that invests in pure-play computing technology companies that derive at least 50% of their revenues from four key segments covered below:
- AI Semiconductors: Companies designing and manufacturing GPUs, CPUs, ASICs, networking chips, and memory solutions that enable AI model training and inference.
- Compute System Enablers: Companies designing, engineering, and producing AI-focused hardware and software systems, including servers, networking, and integration.
- Data Center Infrastructure and Equipment: Companies delivering HVAC, advanced cooling solutions, and specialized infrastructure for energy efficiency and optimal performance in AI data centers.
- Quantum Computing Technology: Companies primarily engaged in the development of quantum computing systems.
The index employs a modified market cap–weighted approach, prioritizing semiconductor leaders while capping individual holdings at 10% to preserve meaningful exposure to smaller, high-growth players across the AI semiconductor and quantum ecosystem. CHPX is also global in scope, capturing both established and emerging semiconductor companies worldwide.
Most importantly, we believe CHPX’s thematic approach allows it to better capture the full stack of next-gen semiconductor and computing innovators, delivering exposure across key market segments that conventional semiconductor ETFs fail to address.
Conclusion: AI Brings a Structural Reset in Semiconductors
AI is driving a once-in-a-generation reset of the semiconductor industry. Specialized processors, high-bandwidth memory, and ultra-fast networking are becoming indispensable building blocks of next-gen computing. The rise of AI supercomputing hubs and the parallel development of quantum technologies expand the opportunity far beyond semiconductors alone. This shift, still in its early innings, could potentially influence trillion of dollars in computing infrastructure spending by 2030. For investors, we believe CHPX offers a differentiated way to access this rapidly developing opportunity.
Related ETFs
CHPX – Global X AI Semiconductor & Quantum ETF
Click the fund name above to view current performance and holdings. Holdings are subject to change. Current and future holdings are subject to risk.